
Google builds a vision-language-action model ‘Robotic Transformer 2 (RT-2)’ that deploys web data and AI in robotics data for enabling robots to do tasks smartly as humans.
The pace of producing an AI or robot that mimic humans’ cognitive and capability is getting faster day by day. Creating a robot that resembles human mind is an arduous milestone that firms are striving to achieve. We have seen Spot, Ameca, Sophia and Tesla’s robot, with specified use-cases but they aren’t in works for domestic uses, except Spot and Tesla’s in some instances.
In a recent approach, Google envisions to combine AI with robots to bring in thinking or understandability to robots to enable them to do basic tasks like washing the fruits, or cleaning the table, especially in the kitchen or in the home.
Robotic Transformer 2
Google unveils this ‘Robotic Transformer 2 (RT-2)’, which is “a novel vision-language-action (VLA) model that learns from both web and robotics data, and translates this knowledge into generalized instructions for robotic control”.
As robots at first, need to understand various objects, environment, task and situation, before getting in hand with the job, Google first preaches AI language model to the robots to make them familiar with things around. The so-called ‘vision language models’ (VLMs) are such AI models trained on web-scale datasets, for tutoring robots to better recognize visual or language patterns to interpret instructions and infer what objects work best for the task. It is also trained to operate across different languages.
Vision-language-action model merges the web data including visual and semantic understanding with robotic data, to instruct robots which ‘joints’ to move for different tasks.

The research by Google’s DeepMind reveals that RT-2 could interpret new commands and respond to user commands better by performing rudimentary reasoning like visual understanding of objects and high-level descriptions.
Teaching Robots
Making robots to do a simple task isn’t an easy process, but requires a systematic and sequential approach that starts from understanding to interpretation and implementation of the task. For example, Cleaning the table might be a basic task for humans, which could be done even by a 5-year-old. But when it comes to robotics, it requires teaching the robot to first choose a suitable material (a cleaning cloth in this case), look for it in surroundings (visual understanding) and handling the cloth appropriately for the purpose.
DeepMind’s RT-2 is also capable of ‘chain-of-thought reasoning’ that allows to perform multi-stage semantic reasoning, like deciding which object could be used as an improvised hammer (a rock), or which type of drink would a tired person ask for (energy drink).
VLM powering RT-2 have also been trained on web-scale data to perform tasks like visual question answering, image captioning or object recognition, which will indeed supplement in robots’ actions. RT-2 adapts Pathways Language and Image model (PaLI-X) and Pathways Language Model Embodied (PaLM-E) to act as its backbones.
RT-2, in contrast to its predecessor RT-1, shows improved generalization performance across all categories, writes its paper.
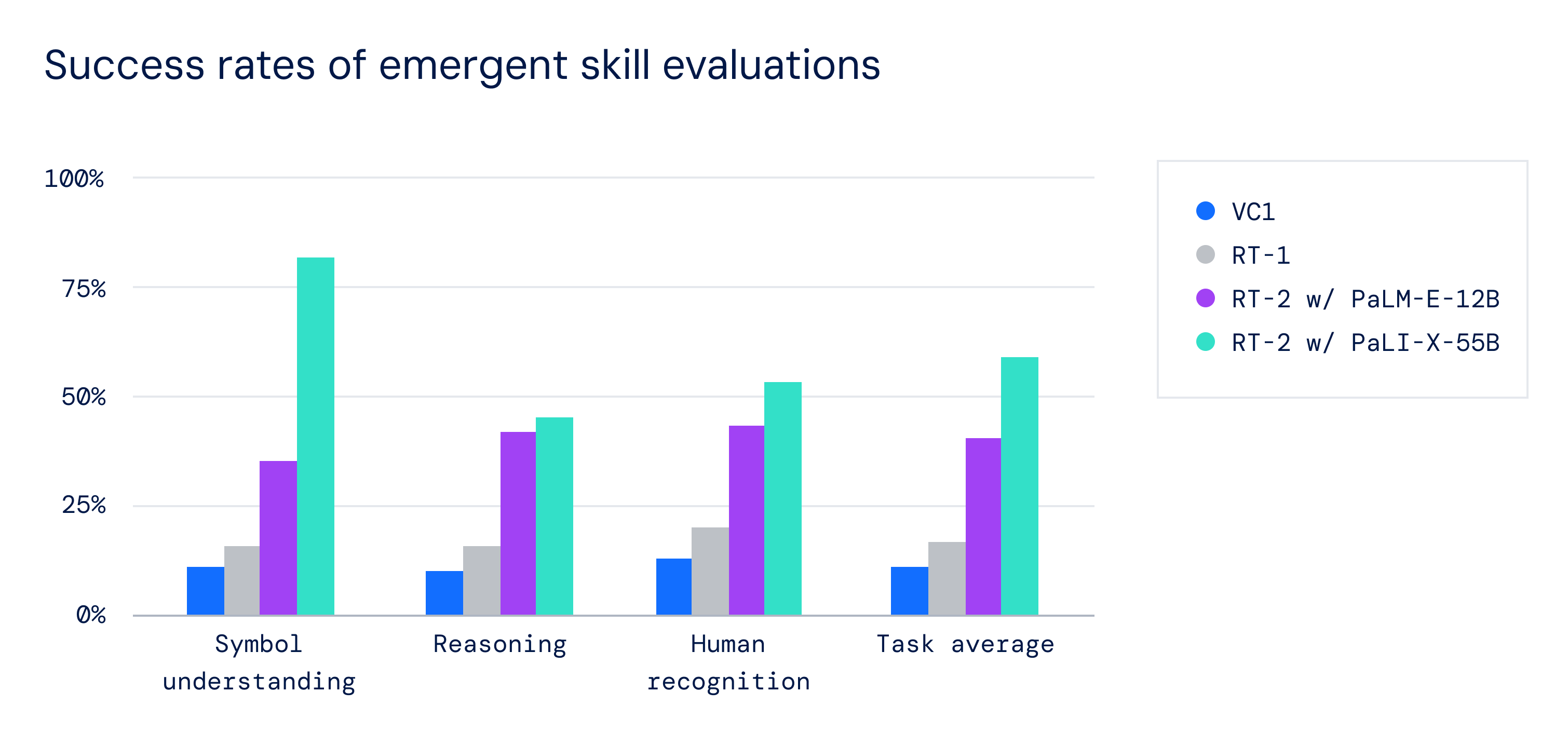
Google’s new robot isn’t perfect. The New York Times got to see a live demo of the robot and reported it incorrectly identified soda flavors and misidentified fruit as the color white. However, it’s learning to be semantic and effective in its performance, with help of VLM and VLA.
Opinion: If everything goes in this pace, Google might create an operating system specifically for robots, which would equip the potentials in any robot – likely as android system in smartphones, as the firm seems to be savant in language models and indeed technology. At all events, robots are coming atleast by 2025.
(For more such interesting informational, technology and innovation stuffs, keep reading The Inner Detail).
Kindly add ‘The Inner Detail’ to your Google News Feed by following us!






