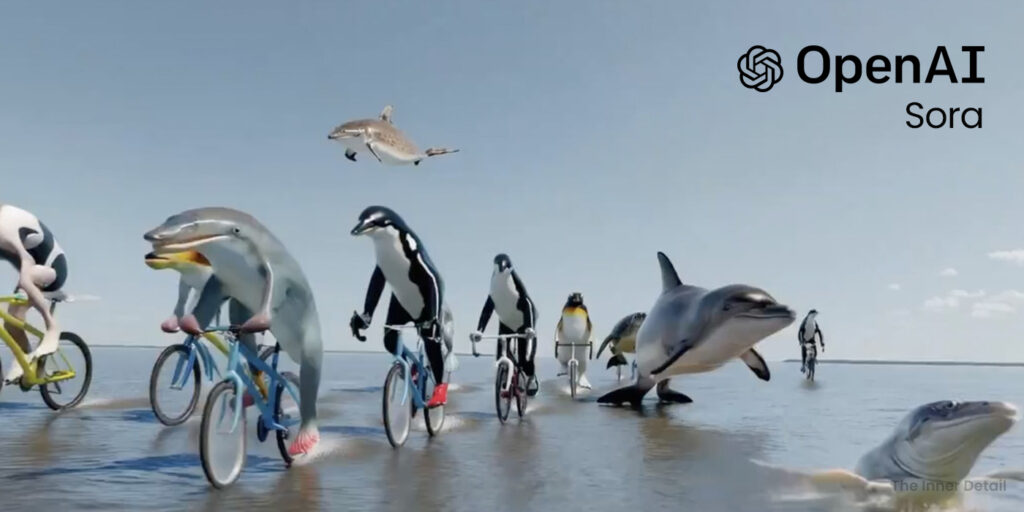
OpenAI has announced its new text-to-video generative AI model “Sora” which can create realistic videos from text prompts or from image and texts.
Amidst many artificial intelligence models releasing in the decade, OpenAI has awed people by unveiling “Sora”, a sophisticated video-generating AI model which is far better in detailing and understanding the prompts. Being the one who incited the AI revolution by releasing ChatGPT, OpenAI had once again garnered attention via this latest model whose generated videos are as natural as real videos, making it difficult to differentiate them.
Sora AI can currently create videos up to 60 seconds directly from text descriptions. To understand the potential and peculiarity of Sora, it’s better to know how Sora actually works. But, before going on to it, let’s see What Sora is all about? And what makes it the state-of-the-art model for generating AI videos?
OpenAI’s Sora
Sora is OpenAI’s new AI model dedicated to generate videos of up to 1 minute long from text prompts or from image and text prompts. It’s capable of creating complex scenes with multiple characters, specific type of motion, details on the subject and background, all with adhering to the prompted texts. Sora strives to simulate how things exist in the physical world and in the aspect, it has come a long way than its peer AI models.
- The model has a deep understanding of language, enabling it to accurately interpret prompts and generate compelling characters that express vibrant emotions. The capabilities of Sora mentioned below are what makes it unique.
- The first thing that makes Sora unique is that the way it works. It fragments a video into smaller units of data called patches, each of which is akin to a token in GPT. It binds the patches together in a sequence just like GPT makes a sentence.
- Sora can create multiple shots within a single generated video that accurately persist characters and visual style.
- Sora can make videos with cool transitions, resembling the work of pro-editors.
- It can not only create videos, but can edit videos by adding elements into it.
- You can also feed a clip of a video and ask it to create as a continuation of it. Sora is capable of doing it.
- Sora creates videos of an unimaginable creativity that pertains to the prompt. It can be used to make animation and cartoon videos that challenges the creativity level of people.
Few experts call Sora as a data-driven physics engine, where it could act as a simulation engine, rendering intuitive physics stuffs and more. Nvidia’s Senior Research Scientist Dr. Jim Fan says, “If you think OpenAI Sora is a creative toy like DALLE, … think again. Sora is a data-driven physics engine. It is a simulation of many worlds, real or fantastical. The simulator learns intricate rendering, “intuitive” physics, long-horizon reasoning, and semantic grounding, all by some denoising and gradient maths.”
How Sora works?
The process of turning text prompts into video by Sora involves four steps – turning visual data into patches, video compression network, spacetime latent patches and scaling transformers for video generation.
Sora’s peculiarity is how it renders videos in a way that is similar to how sentences are formed in GPT-4. At first, each frame of the training videos is divided into small visual patches, just like words are broken down into tokens in the LLMs. This is done by compressing the videos into a lower-dimensional latent space and decomposing the representation into spacetime patches.
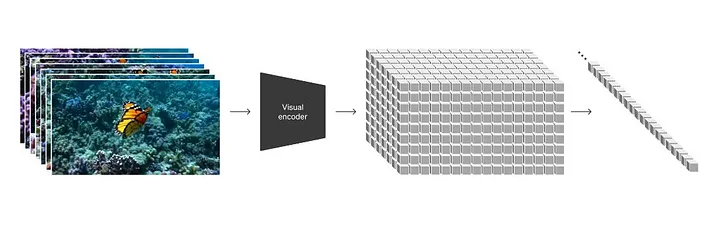
A network is trained to reduce the dimensionality of visual data, which compresses a video temporally and spatially to a raw form, decreasing the data set’s complexity. Then sequences of spacetime latent patches are extracted to form an image first.
(Temporal compression – reducing file size by removing redundant or irrelevant information like motion vectors, frame rate.
Spatial compression – reducing the file size by removing information like color depth, detail level.)
Sora AI is a diffusion transformer model, which means by providing an input of noisy patches, it’s trained to predict the original clean patches, explains OpenAI’s research site. Transformer aspect of Sora helps it to transform an input sequence into an output sequence, by learning context and tracking relationships between sequence components. Here, the patches are sequenced accordingly to be rendered as a video.

And the whole thing happens in a matter of seconds.
How to use Sora AI?
Sora is limited to few people called red teamers for testing the AI on critical areas of harm or risk and a number of visual artists, designers, and filmmakers to gain feedback on how to advance the model to be most helpful for creative professionals. Sora is not available to public currently. However, it might be available in future, but for a cost.
(For more such interesting informational, technology and innovation stuffs, keep reading The Inner Detail).
Kindly add ‘The Inner Detail’ to your Google News Feed by following us!






